




The main function of a software keyboard is to show the most common keys in any given language and translate each "touch input" into an "expected word". The way a keyboard presents the keys is called a layout and, nowadays, even the simplest keyboard you can download support several layouts per language (ex. QWERTY, AZERTY, QWERTZ, ...).
Today, it is paramount that a mobile keyboard should be fast, CPU efficient and with its memory usage under control in order to prevent an inevitable eviction by the mobile operating system (OS).

Nowadays, the minimum input method supported by a software keyboard is "tap typing", where one user can tap the keys corresponding to the characters of a word. Next to these common virtual keyboard, you can find more advanced keyboards that support "swipe typing", where users swipe their finger across the keyboard.
Let me share these 2 different input methods.
Tap typing
For "tap typing", the user is subject the following challenge: while trying to touch the desired keys, the keyboard needs to guess what are the most probable sequence of characters. This process, based on one or several dictionaries, uses autocorrection on-device models to prevent undesired lags in the input experience.
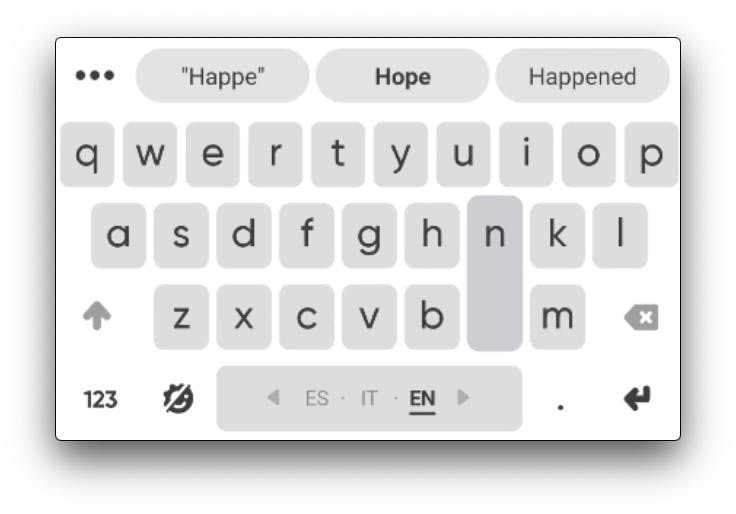
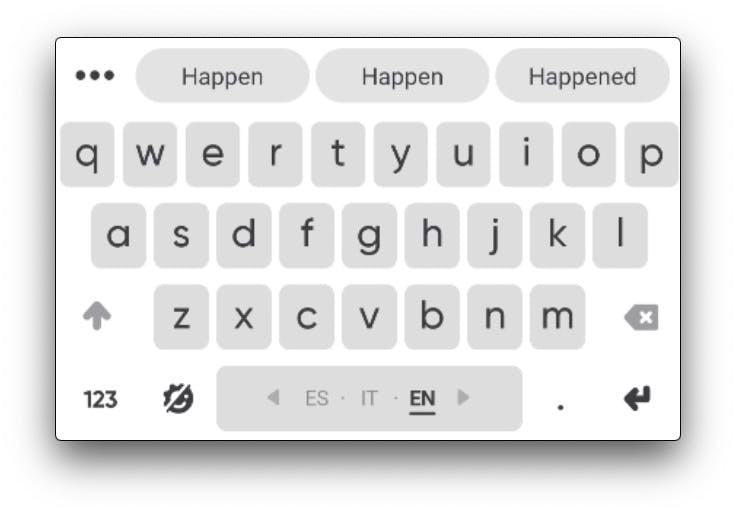
Usually, this "decoding process" suggests several word candidates to the user ordered by a probabilistic scoring method. This score is usually calculated by a spatial probability model (how far each point is from each desired key) and a language model. In such case, a threshold is applied to determine the probability of an "out of vocabulary" (OOV) word, presented to the user as a good decoding candidate.
Swipe typing
In the case of "swipe typing", the user touches the first letter of a word and continues "swiping" or "moving" his finger from one letter to the other. When the user lifts his finger, several decoding candidates are shown to the user, each ordered by a score.
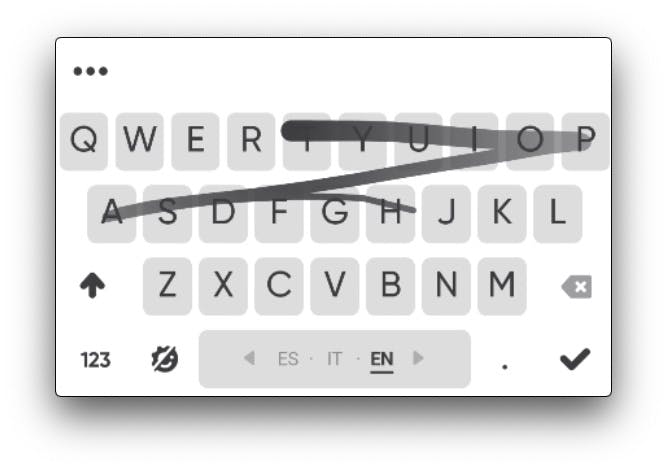
In this case, the score is calculated by a spatial probability model where each point of the swipe is taken into account.
To decide which words are the best fit to decode, we use a beam search algorithm with an aggressive pruning of invalid search paths. For us, an invalid search path is a path of points with a decoding probability lower than the threshold calculated using real data from our users. These search paths are built using one or several dictionaries of valid words in what's called a "Directed Acyclic Graph" (DAG) optimized data structure.
Since a normal language dictionary can contain tens of thousands of words, our method takes this into account in order to instantly prune the invalid search paths, saving Memory and CPU consumption.
Pseudo code
The following is the pseudo-code for our algorithm:
new_path = path()
beam = empty_beam()
# Add alignment search path to all the possible first letters
for starting_letter in starting_letters:
beam = add_alignment_search_paths(starting_letter,
beam,
new_path,
point)
for point in swipe_path[1:]:
next_beam = empty_beam()
for search_path in current_beam:
# Add alignment search path for the same letter
next_beam = add_alignment_search_paths(search_path.prev_letter(),
next_beam,
search_path,point)
# Add transition search path for the same letter
next_beam = add_transition_search_paths(next_beam,
search_path,
search_path.prev_letter(),
search_path.prev_point(),
point)
if search_path.isAlignment():
# Add transition search path for all the possible next letters
next_letters = get_next_letters_from_path(search_path)
for letter in next_letter:
next_beam = add_transition_earch_paths(next_beam,
search_path,
letter,
search_path.prev_point(),
point)
curr_beam = next_beam
curr_beam.sort_by_prob()
curr_beam = curr_beam.truncate(beam_size)
return curr_beam.truncate(max_candidates)
Key aligments and key transitions
The functions add_alignment_search_paths and add_transition_search_paths are responsible of adding a new search path to the current beam. This new search path added next to the beam contains the current path in the DAG (a word prefix) with the accumulated probability for this path. Search paths with the same prefix can't exist. Only the one with the best score is kept.
For add_alignment_search_paths, it is a function that calculates what is the probability for the point and its alignment to a specified key (letter). This probability is calculated by using a gaussian probabily density function (GDPF) applied to the distance between the specified point and the center of the specified key. The gdpf parameters have been adapted to specific dimensions and users typing habits.
For add_transition_search_path, it is a function that calculates what is the probability for the point as a transition from a previous point to a specified key (letter). This probability is calculated using a GDPF applied to the angle between the vectors pp->cp and pp->k, where pp is the previous point, cp the current point considered and pk the centre of a specified key.
When all the points of the swipe path have been consumed, the algorithm then scores the remaining candidates with a ngram language model.
Example of application
In this example we apply the pseudo-code's invention to a real case sceneario: swipe typing the word "happen".
Prerequisites
For this example, we assume that we currently have a simple dictionary including the following contents:
- gas
- happen
- happem
We then use a simple unigram language model where we have the probability of each word to occur:
- gas: 0.3
- happen: 0.5
- happem: 0.2
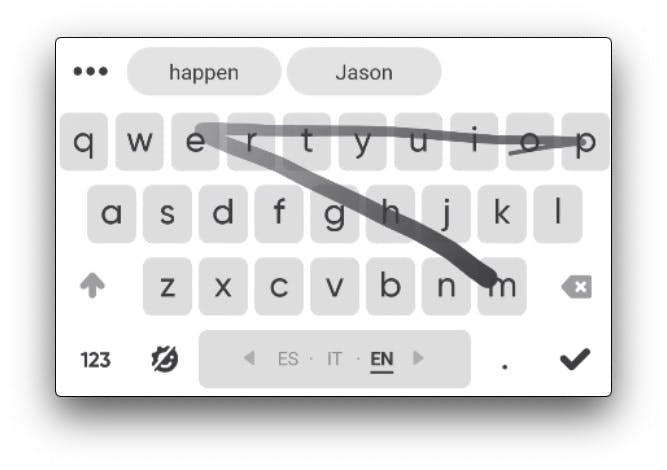
Example swipe path
The swipe path that belongs to the word "happen", which needs to be decoded, is shown in the following illustration:
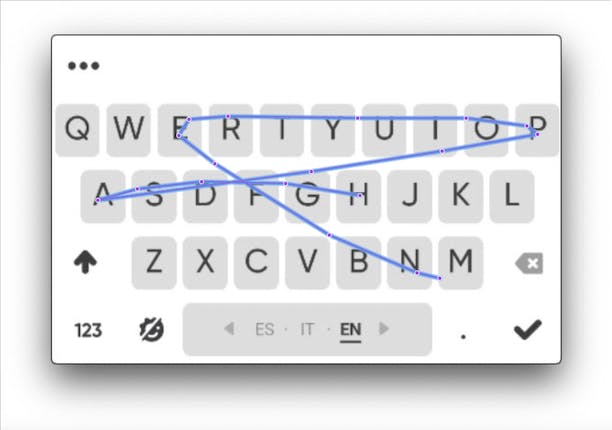
For clarity, we can label each point belonging to the swipe path with its order. As you can see, the distance between points depend solely on the speed of the user and the decoder should be robust to the swipe typing habits:
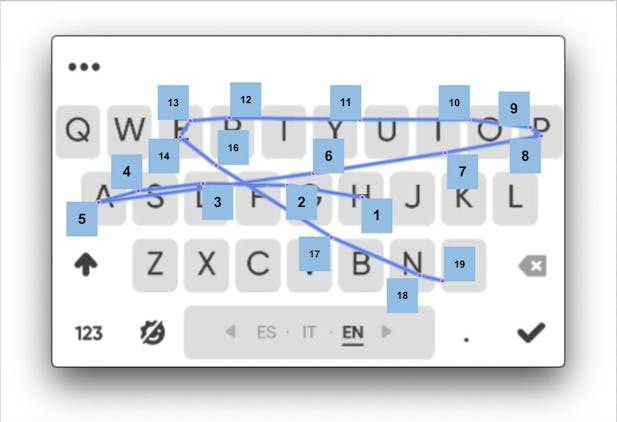
Pseudo-code walkthrough
Following the pseudo-code we start with the starting point of the swipe type (point 1).
for starting_letter in starting_letters:
beam = add_alignment_search_paths(starting_letter,
beam,
new_path,
point)
We can consider the variable 'starting_letters' as all distinct letters that start a word existing in the dictionary. In the dictionary for this example, these letters will be "G" and "H".
The function "add_alignment_search_paths" will add as search paths to all alignments to the 'starting_letters'. As we have 2 possible starting letters, we'll have in the current list of candidates (current beam) the following search paths. The score for each search path is the probability of the point '1' being aligned to the center of the key 'h' or the key 'g'.
current_beam
- letter:'h', score: 0.9, prev_point: 1, type: alignment
- letter: 'g', score: 0.2, prev_point: 1, type: alignment
N.B.: The scores or probabilities shown in this example are simplified for making the example easier to understand.
We then enter in the main loop that will go through all points of the swipe path, starting with the point labeled as '2'. Each point will build a new beam based on the current beam. In our example, the first iteration of this loop will have a beam with the two previous search paths.
for point in swipe_path[1:]:
next_beam = empty_beam()
for search_path in current_beam:
For each search path in the current beam, we need to add a new search path with a possible alignment with the same letter of the search path as well as a transition to the same letter. For simplicity, we need to process all the search paths at the same time.
# Add alignment search path for the same letter
next_beam = add_alignment_search_paths(search_path.prev_letter(),
next_beam,
search_path,
point)
# Add transition search path for the same letter
next_beam = add_transition_search_paths(next_beam,
search_path,
search_path.prev_letter(),
search_path.prev_point(),
point)
next_beam
- prefix:'h', score: 0.45, prev_point: 2, type: alignment
- prefix:'g', score: 0.4, prev_point: 2, type: alignment
- (discarded) prefix:'hh', score: 0.9, prev_point: 2, type: transition
- (discarded) prefix:'gg', score: 0.9, prev_point: 2, type: transition
Search paths 3 and 4 are discarded as there are no words starting with 'hh' or 'gg'. Discarded prefixes won't be shown in the future.
Then we add all possible transitions to another letter (based on the dictionary):
if search_path.isAlignment():
# Add transition search path for all the possible next letters
next_letters = get_next_letters_from_path(search_path)
for letter in next_letter:
next_beam = add_transition_earch_paths(next_beam,
search_path,
letter,
search_path.prev_point(),
point)
The function 'get_next_letters_from_path' will return the letter 'a', as it is the only candidate to follow 'g' or 'h' inside our dictionary:
next_beam
- prefix:'h', score: 0.45, prev_point: 2, type: alignment
- prefix:'g', score: 0.4, prev_point: 2, type: alignment
- prefix:'ha', score: 0.8, prev_point: 1, prev_letter: 'h', type: transition
- prefix:'ga', score: 0.5, prev_point: 1, prev_letter: 'g', type: transition
Then, we need to sort the remaining search paths by score and only keep the beam_size. This will be the next beam we’ll process in the next iteration:
curr_beam = next_beam
curr_beam.sort_by_prob()
curr_beam = curr_beam.truncate(beam_size)
curr_beam
- prefix:'ha', score: 0.8, prev_point: 1, prev_letter: 'h', type: transition
- prefix:'ga', score: 0.5, prev_point: 1, prev_letter: 'g', type: transition
- prefix:'h', score: 0.45, prev_point: 2, type: alignment
- prefix:'g', score: 0.4, prev_point: 2, type: alignment
We can follow the same process with the rest of the points. We'll show the point processed and the resulting beam:
Point 3 curr_beam
- prefix:'ha', score: 0.8, prev_point: 1, prev_letter: 'h', type: transition
- prefix:'ga', score: 0.5, prev_point: 1, prev_letter: 'g', type: transition
- prefix:'g', score: 0.3, prev_point: 2, type: alignment
- prefix:'h', score: 0.2, prev_point: 2, type: alignment
(take into account that some prefixes can be discared if the score is too small)
Point 4 curr_beam
- prefix:'ha', score: 0.7, prev_point: 1, prev_letter: 'h', type: transition
- prefix:'ga', score: 0.4, prev_point: 1, prev_letter: 'g', type: transition
Point 5 curr_beam
- prefix:'ha', score: 0.8, prev_point: 1, prev_letter: 'h', type: transition
- prefix:'ga', score: 0.5, prev_point: 1, prev_letter: 'g', type: transition
Point 6 curr_beam
- prefix:'hap', score: 0.8, prev_point: 5, prev_letter: 'a', type: transition
- prefix:'gas', score: 0.4, prev_point: 5, prev_letter: 'a', type: transition
- prefix:'ha', score: 0.3, prev_point: 6, type: alignment
- prefix:'ga', score: 0.2, prev_point: 6, type: alignment
Point 7 curr_beam
- prefix:'hap', score: 0.7, prev_point: 5, prev_letter: 'a', type: transition
- (discarded) prefix:'gas', score: 0.1, prev_point: 5, prev_letter: 'a', type: transition
(word "gas" is going to be discarded as point 6 and point 7 are leaving the 's' letter)
We continue the same processing until we reach the last point (point 19) with the following curr_beam:
Point 19 curr_beam
- prefix:'happem', score: 0.8, prev_point: 19, type: alignment
- prefix:'happen', score: 0.7, prev_point: 19, type: alignment
As this is the final step, we have two candidates that we need to score with the probability coming from language model:
- 0.8 Plm(happem) = 0.8 0.2 = 0.16
- 0.7 Plm(happen) = 0.7 0.5 = 0.35
So, the final decoding candidates will be:
- prefix:'happen', score: 0.35, prev_point: 19, type: alignment
- prefix:'happem', score: 0.16, prev_point: 19, type: alignment
Comparision with other methods
Our swipe typing decoding uses only geometrical information. This approach uses far less CPU than other methods where speed is privileged. Thanks to the usage of all points inside the swipe path as well as the score calculation of each search path, our method is much more resilient to abnormal movements from the users' finger.
As a fact, other methods don't use every swipe path points and use instead some heuristics to decide which points are the best fit for a swipe trajectory. This is not required in our case.
Future work
The parameters used by the algorithm (like the beam size and the pruning thresholds) have been calculated using cross validation with swipe data from real users in different languages. In the future, this data can definitely be used to further refine other languages as well to optimize the performance for continuous swipe decoding.
We have plans to use a DAWG (directed acyclic word graph) in order to easily accommodate OOV words using the DAGW as a character-based language model during the decoding process. This will allow us to improve the pruning method even more.
Experiments
Our experiments shows that our methods are better in terms of flexibility, speed and memory consumption. In fact, it is a leap in performance compared with using Deep Learning techniques like recurrent neural networks or, transformer models like the Connectionist Temporal Classification (CTC) beam search.
Previous work on our side using such models have shown an increase of 10x in memory consumption and CPU usage, with only one layout per language. With such results, we fully abandoned using these "new techniques" to more proven and reliable ones.