


Ensuring high-quality auto-correction for 80+ languages
Deep diving into how Fleksy utilizes machine learning to ensure our keyboard features provide a high-quality benchmark


Fleksy builds virtual keyboards with features such as auto-correction, auto-completion, next-word prediction, etc. These powerful features empower users to communicate better with others. However, as the saying goes, "With great power comes great responsibilities" testing these features to ensure a high-quality benchmark is very important. This article shares how we at Fleksy achieve that.
This article is an excerpt from the original article published on Fleksy's blog, initially written by Nicolas Remond. To read the original blog, please check it out here.
The Need for Automated Benchmark
Getting feedback from users for a product is always the best way to measure its quality. However, the majority of the time, this is not possible due to constraints such as:
- Frequent releases requiring frequent quality assessments
- Over 80 languages to assess
- Quality assessments need to be repeatable
- Quality assessments should be unbiased
Due to the above-mentioned reasons, it is better suited to automate this process instead of doing it manually with users (human testers).
When it comes to automated testing, there are plenty of existing open-source libraries and projects. However, none of them covers the essential tasks that we, as virtual keyboard maker, requires. That's why we devised our benchmark system specific to virtual keyboards and their tasks, essentially focusing on the following:
- Auto-correction
- Auto-completion
- Next-word prediction
- Swipe gesture resolution
We use this benchmark devised by us to compare quality across our version and our competitors.
The Devised Benchmarking
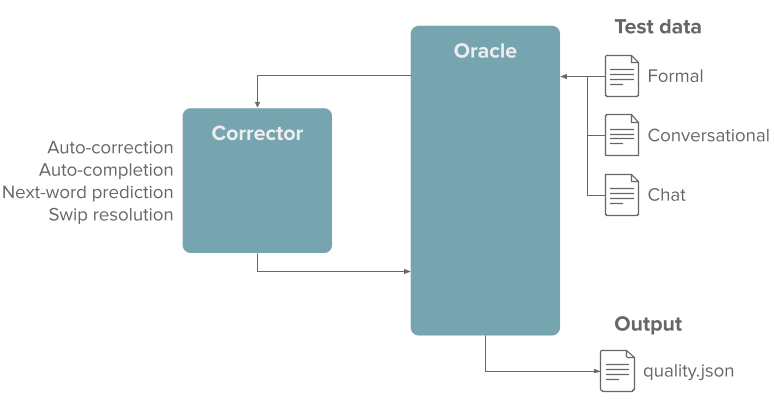
The Oracle takes the clean data as input, transforms it for each task, and sends it as input to the Corrector. The Corrector is simply the model to test, and it returns its output to the Oracle. Afterward, the Oracle scores this output and computes overall metrics that are then saved in a JSON file.
Tasks, Typos, Measurement, and Metrics
Out of the multiple features and tasks offered by a virtual keyboard nowadays, there are mainly four essential tasks:
- Auto-correction: Corrects the words typed by the user. E.g., if a user types
I’m especialy touched, the typo should be detected and corrected toI’m especially touched. - Auto-completion: Completes the word typed by the user. E.g., if a user types
I love y, the word should be auto-completed toI love you. - Next-word prediction: Predicts the next word to be typed. E.g., if a user types
I want to eat french, a probable next word can befries. - Swipe gesture resolution: Predicts the word from a swipe gesture.
For every language, we use the following sources to generate the data over which benchmarking is performed :
- Formal: Data that comes from official, public datasets.
- Conversational: Data scrapped from online content, such as movie lyrics.
- Chat: Data gathered directly from our users testing the keyboard.
Fleksy currently boasts data for each of the 80+ languages supported by our SDKs that we need to test.
The data used as input for these tasks is completely clean initially. Typos are introduced to mimic the flow of a user's typing experience on a virtual keyboard. Afterward, features and tasks are observed to see how they react to the data.
- For auto-correction, we introduce typos in the clean text and see how the typo would be corrected.
- For auto-completion, we input only part of a word (with or without typos) and see how the word is completed.
- For the next-word prediction, we input a partial sentence and see how it is completed.
- For swipe gesture resolution, we generate a list of swipe gesture points and see if the resolved word corresponds.
To continue reading how the benchmarking process works in depth with transforming data, mimicking typos made by users, measuring the output, and communicating the metrics, please read the full blog on our website here.
To discuss this article, our benchmarking process, or any questions, don't hesitate to contact us via comments. We are also on Discord here, where you can discuss any tech topic and follow the latest news about development with our team.