




Language modelling has come a long way in recent years. But modelling languages is difficult, even for today’s advanced AI engines. AI is far better equipped to handle images than language, as language is ever-evolving and words and phrases have multiple layers of meaning depending on context, which makes it highly complex to accurately predict.
However, if your app or software program uses a touch-screen keyboard, then you’ll be interested to know that there have been some big improvements in how accurately the next words in a sentence are predicted.
These improvements have come about as a result of advancements in the AI-driven language modelling that we use as part of our Fleksy SDK.
What is a language model?
Language modelling refers to the statistical process that is used to predict the next word in a sentence before it is typed. Language models apply a probability distribution to the words already typed in a sentence to work out the most likely word to come next.
For example, if the words already typed are “Nice to meet”, then it is highly likely that the word “you” will come next. We know this intuitively, but a good language model uses a finely-tuned encoding method and probability distribution to spot patterns in the previous words and identify words that are likely to come next.
It does this by ranking words by likelihood. For the example given above, the language model may score “you” as the most likely, “your” as the next most likely, “his” or “her” next, and so on. The predictive text feature that is built into the keyboard will then suggest the word “you” to the user.
Autocomplete features are also commonly used in touch-screen keyboards. Using the same example, if the user has already typed the letters “yo”, the language model will search through all the possible words and rank them in terms of likelihood. The ranking may include words such as “yoghurt” and “youthful”, but if the language model is statistically sound, it will offer the word “you” as an autocomplete option.
Word prediction challenges
As things stand at the moment, language modelling and word prediction technology is advancing rapidly, but to achieve high levels of accuracy it takes large amounts of processing power.
For example, the highly sophisticated transformer models developed by Google and Open AI have been trained on more than 1.5 billion parameters, making them far too big and resource-intensive to be of practical use on standard computers or devices.
How does the Language Model affect Autocorrect?
Before we move on to how Fleksy has improved the accuracy of the language model, it’s important to also realise that this can help to improve the autocorrect feature of a touch-screen keyboard.
For example, let’s imagine that a user wants to type “Good luck”, but mistakenly types “Good lick”. An autocorrect engine that relies on a poor language model may not pick up the mistake or may suggest unlikely alternatives such as “lock” or “lack”. A good autocorrect feature will realise that “luck” is more likely, especially given that the letters “u” and “i” are next to each other on a QWERTY keyboard.
Improvements to Fleksy’s Language Model
We have made several improvements to our language model that have increased the accuracy of our autocompletion, next word prediction, and autocorrection. These improvements are best demonstrated by taking a look at some examples.
Autocompletion improvements
The old autocompletion engine often gave inaccurate predictions and suggestions. Here are some comparisons between the behaviour of the old autocompletion engine and the new one that uses an improved language model.
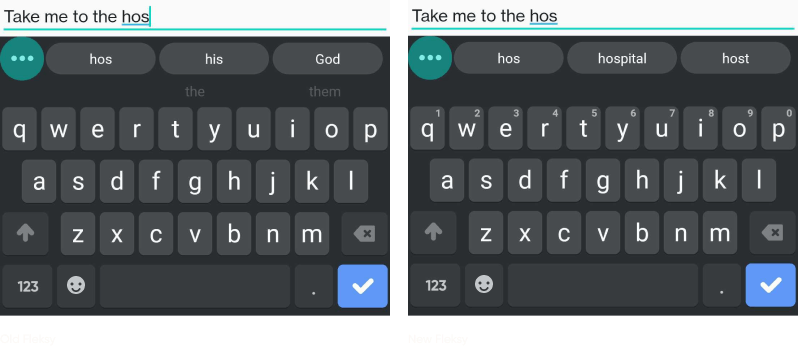
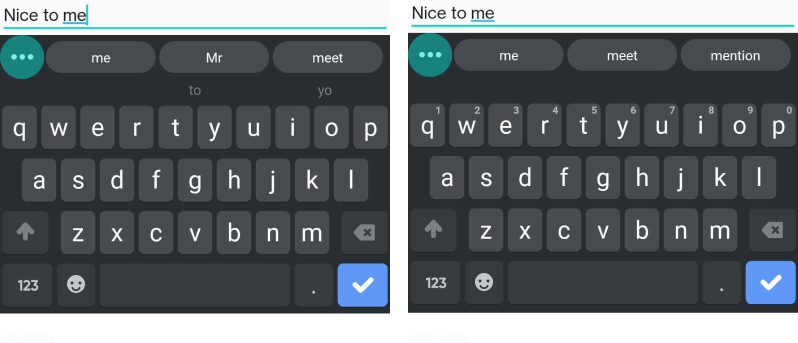
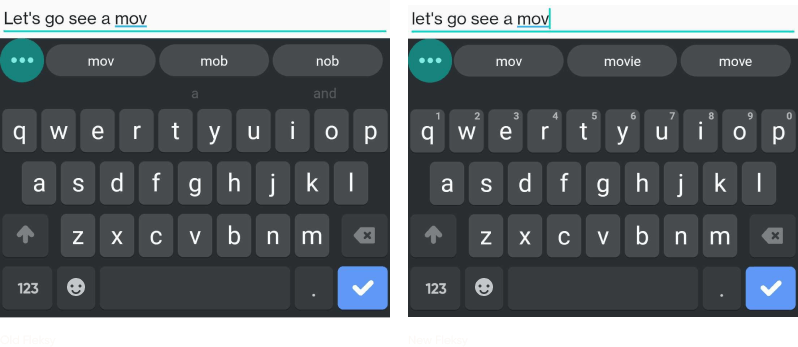
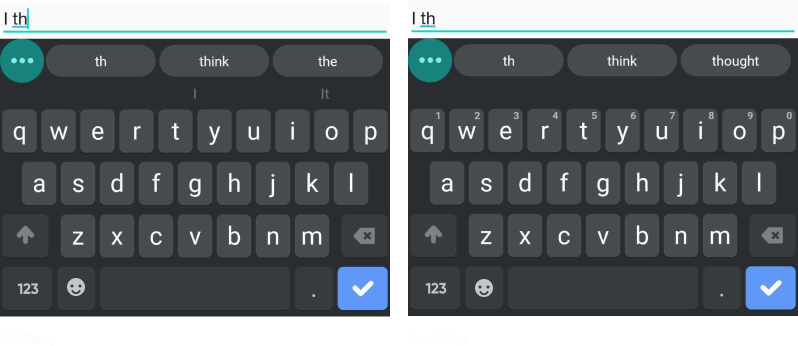
As you can see, there have been two main improvements:
- Better selection of candidates as can be seen by the suggestion of “hospital” rather than “his” or “God”, as well as “movie” instead of “mob” and “nob”.
- Better use of the language model as can be seen by the suggestion of “think” and “thought” rather than “the”, as “I the” is a highly unlikely way to start a sentence.
Next Word Prediction
In Fleksy the next word prediction feature uses a different system than autocomplete. Although the original next word prediction engine wasn’t too bad, there were still occasional issues, especially the way the next word prediction feature behaved when the autocomplete was triggered, as can be seen below.
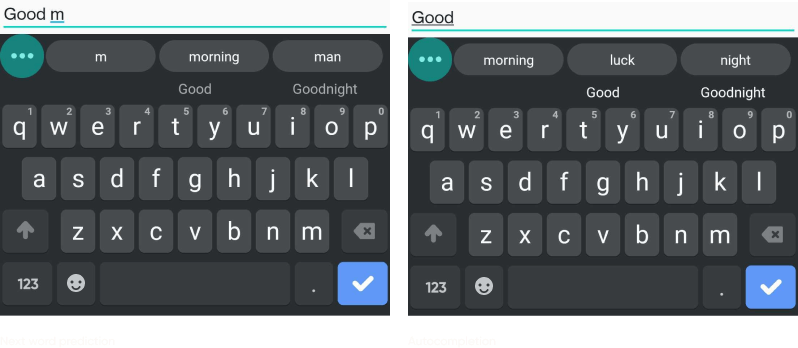
In the left image, we can see that the next word prediction is quite good.
Now in the second image, the user has started to type the word “morning” (without clicking the next word prediction). In other words, they have typed the next character, which is “m”. We would expect that “morning” would still appear as the first suggestion in the top bar, since we would be autocompleting “m”, given the context “good”. We can see that this does not happen.
The word “Morning” still appears but with a lower score than “my”. As was explained in the previous paragraph, next word prediction and autocomplete rely on two different systems, which explains why one used to perform well and the other not so well.
Here are some more examples so you can see that this was a common problem, especially with longer words.
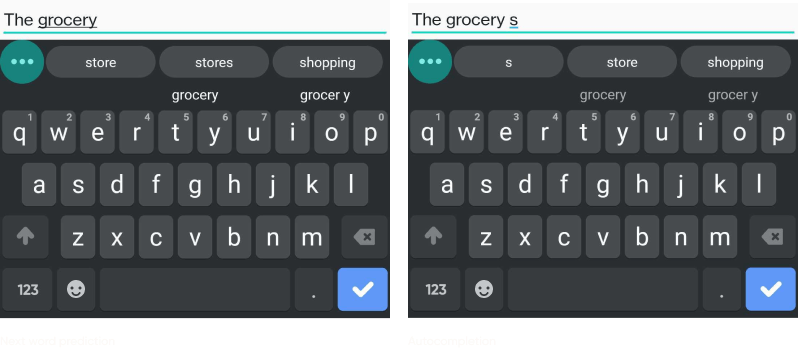
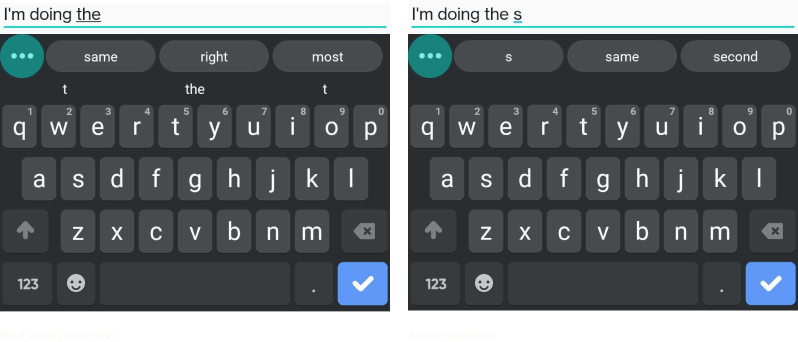
Thankfully, this issue has now been fixed by replacing both systems with the new language model. In other words, both the next word prediction and autocomplete features use the same system and give more accurate results.
Here are the same examples as before but using the new system.
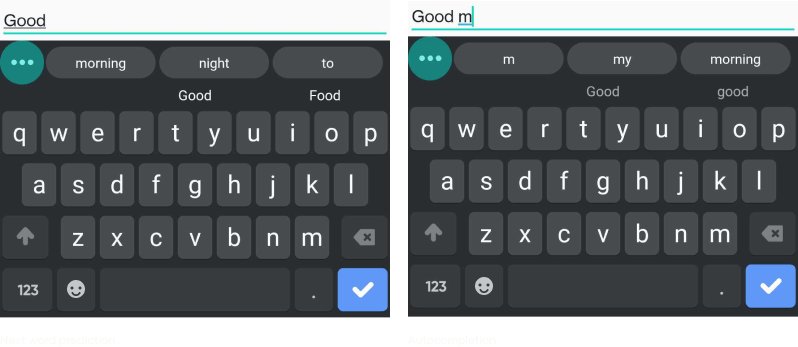
Summary
The latest language model updates to the Fleksy SDK have helped to improve the accuracy of the next word prediction and autocomplete features. Given the complexity of language modelling, it is impossible to achieve 100% accuracy at the moment, but we’re getting closer and closer to near-perfection, which is great news for both app-owners and app-users alike.